面对大量文本数据时,分类处理是个绕不开的问题。手头刚好就有个类似的小项目,所以来捋捋我尝试过的三种文本分类处理方案。
手动标记
这是最基础,也是最原始的处理方案。它使用人工的方式来编辑并设置文本数据的分类。很多个人博客甚至 CMS 文章管理系统中都是采用的这种方式。
手动标记的方式好处是数据分类精准,逻辑清晰,功能开发简单;缺点是依赖于人力,不太适合随时都有大量数据的场景。
关键词自动绑定
关键词自动绑定是一种适合于大量数据的自动化的分类方案。它的核心操作逻辑如下:
- 提取待分类文本的关键词(也就是分词操作)
- 给分类定义好核心关键词
- 程序自动查找待分类文本和分类中定义的核心关键词,如果两者匹配,就把文本归入分类
从上面的流程可以看出,它比手动标记「自动化」了一步,可以不用人工对每篇文章来手动定义分类,但取而代之的是需要人工管理分类的核心关键词。
在待分类的文本数据关键词不是很宽泛的场景下,这种方案用起来也还不错。一旦数据涵盖的内容类型或是分类比较多时,就感觉有点疲于应付了。
贝叶斯分类算法
贝叶斯算法是我目前比较青睐的海量数据文本分类处理方案,它通过概率的方式来解决我上面提到的一些需要人工编辑的问题。
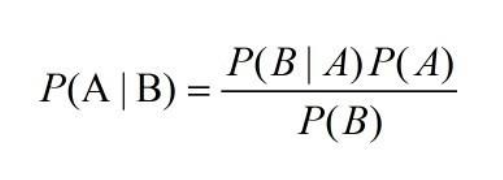
关于这个算法的介绍文章有很多,我不准备再重复叙述。总体来看它算是一个比较简单的算法。以文本分类的场景举例,我只需要做好以下几项准备工作:
- 提取待分类文本关键词
- 计算关键词属于各分类的概率
- 计算各分类的全局概率
- 汇总待分类文本关键词和各分类全局概率的联合概率,并按大小排序,概率数值最大的分类即是文章可以绑定的分类
理论上来说,使用贝叶斯算法分类时不需要任何人工参与。但在前期数据量不足,概率计算模型还没建立好时仍然还是离不开人工的参与。比如在最开始的阶段,就需要人工先分好一些文章分类,然后通过这批数据来让贝叶斯算法有数据可计算概率。
因为是基于概率,所以分类的准确度自然无法达到 100%,通常接近 80% 的准确度就已经是一个不错的结果。不过我觉得这个结果应该会随着数据量的提升而提高,理想情况下这个百分比应该会超过 80%。
在实际使用时,我目前碰到需要人工干预的情况主要来自大量跨分类且无意义的关键词,它们会干扰分类结果。比如「使用」这个词,对确定分类其实没有任何帮助,所以需要想办法排除这类关键词的影响。比较粗暴的解决方法是在分词时就通过各人工词库来删除这类词,但这显然又陷入了上面第二个分类方案中的困境。所以更加理想的方案是引入 TF/IDF 算法来确定待分类文本的核心关键词。