最近琢磨着想给手头的一个实验项目添加相关推荐的功能。因为要推荐的数据对象有标签数据,所以就准备从标签信息来入手,看看如何来完成相似性的关联。在经历了一番摸索后,我了解到了「余弦相似度」算法。
手头的这个实验项目是一个博客聚合网站。我个人有爱逛博客的习惯,特别是一些独立个人博客。所以也是基于自己的需求开发了这样一个小项目。项目访问地址如下:
阅读这些个人博客内容的体验不同于一些内容平台,因为是作者自己的领地,没有流量的追捧,内容输出全看心情。所以你能看到一些发自内心的知识总结和生活分享。他们把各自平凡而又多姿多彩的一天凝聚成真情实感的文字,我为此着迷。
这种体验不是在一些流量平台上基于算法编织出的「信息茧房」所能提供的。所以每天我都会花不少时间在这个小项目上。看看当天有些什么新发布的文章,然后也会琢磨着可以添加点什么有意思的功能。今天提到的这个推荐功能其实就是其中的一个小想法。
这个项目收录了一些博客站点。每个站点都提供了一个详情页面,我的想法是当看到某个感兴趣的博客时,能够知道在收录的这些博客中,有没有在内容方面比较接近的其他博客站点。所以这个功能的目的说简单点就是希望能实现博客站点的关联性推荐。
比较原始的方式就是对博客站点的关联信息进行「人工」处理。但这不仅难于维护,而且从过程上来看非常主观。也许我今天觉得 A 和 B 好像类似,但随着 B 发表了几篇不同的内容,两者的相似性逐渐变弱了。难于维护的问题体现在随着站点数量增加,这项工作的耗时也会「指数级」增加。所以这个方法不可取。
另一个方案就是给站点定义内容标签,然后根据每个站点的内容标签求「并集」。拥有相同内容标签越多的站点,相似度必然越高。
这是个值得一试的方案。不过要考虑的是如何给每个站点定义内容标签。如果手动给每个站点分配,就会出现和上面原始方案相似的「维护性」问题。不过考虑到定义标签的参考依据是站点发布的内容,那么直接通过程序提取内容的关键词,然后合并再提供给站点作为内容标签来使用,看起来就很可行了。
根据这个想法,在进行相似度推荐之前,我通过分词的方式,搞定了站点的内容标签。这个标签会根据站点发布的内容自动更新。所以从维护方面来看,基本没有什么工作量。接下来,我只需要搞定如何获取两个站点内容标签的「并集」,并分配一个相似度数值,以提供给查询语句使用,这个功能流程就算是打通了。
求「并集」在我脑海里首先冒出来的方法同样比较原始。就是把两个站点的内容标签取出来,然后通过数组匹配的方式来确定相同项。根据相同项的多少分配一个数值,用来代表相似度的权重值。
考虑到这个方法过于「粗糙」和低效,暂且把它作为一个「兜底」方案。以「相似度算法」为关键词,了解了一下更「高级」的算法。「余弦相似度」就是其中之一。
因为这个算法中有「余弦」二字,我花了点时间在三角形函数中的「正弦」和「余弦」概念上,主要是想搞清楚这个算法的来历。结果发现好像也没多大关系。数学底子差,一个简单的余弦推导就把我给整懵了。
所以不妨直接一点直面需求:我该如何使用这个公式?
万幸这是一个十分普及,且十分简单的算法,稍微搜索一下后就得到了答案。不提公式了,直接上数据和计算方法。
首先假设有 A, B 两个站点,他们目前的内容标签数据如下:
- A:
['编程', '摄影'] - B:
['编程', '旅游']
在开始计算这两个标签组之前,需要先把它们的内容进行合并,变成一个「参照」数据,这个参照数据必须包含两个对比数据的所有标签内容。上面两组内容标签的参照数据合并后如下:
['编程', '摄影', '旅游']然后对照这个参照数据的顺序,获取对应标签包含的文章数量为计算因素。假设 A 站点有 8 篇编程的文章,3 篇旅游的文章。B 站点有 3 篇编程的文章,6 篇旅游的文章。根据上面参照数据顺序生成后的数据如下:
- A:
[8, 3, 0] - B:
[3, 0, 6]
接下来就是根据余弦相似度公式来计算这两组数值的相似度了。把这两组数据代入公式:
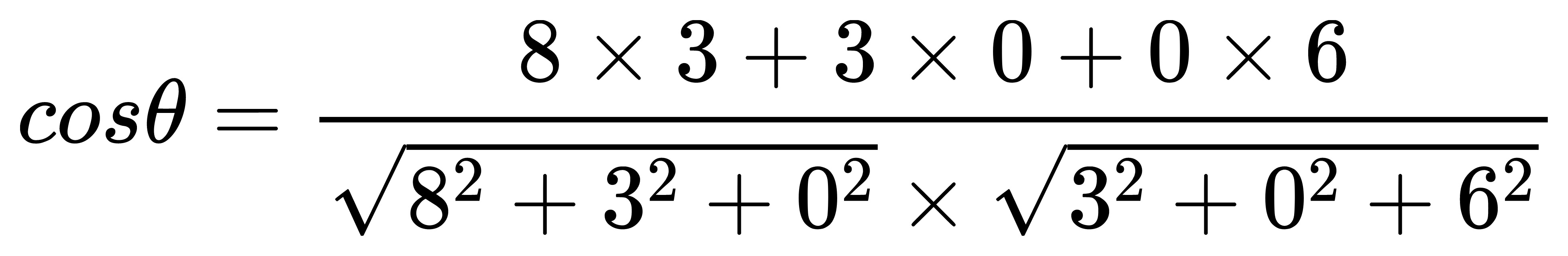
至于公式转换成代码后的计算过程,用 PHP 实现如下:
<?php
$a = [8, 3, 0];
$b = [3, 0, 6];
$molecular = 0;
$aSqr = 0;
$bSqr = 0;
foreach ($a as $i => $v) {
$molecular += $v * $b[$i];
$aSqr += pow($v, 2);
$bSqr += pow($b[$i], 2);
}
var_dump($molecular/(sqrt($aSqr)*sqrt($bSqr)));这是上面代码计算后的结果:

余弦相似度的结果取值在 0 ~ 1 之间。越靠近 1 代表相似度越高。以上图中的这个结果为例,如果 1 代表完全相似,0 代表完全不相似。那么这两个站点目前的相似度其实并不高。所以这就牵涉到使用这个算法时的另一个问题:阈值。也就是我要获取和 A 站点相关的其他站点时,需要定义一个「临界值」来作为是否符合「相似」的标准。
这个值需要综合实际的数据来动态调整。设置的过高会导致得不到任何相似性推荐数据,过低会出现大量「弱相似性」数据。