
我有每天看 Nginx 访问日志的习惯,默认文件形式的 Nginx 日志只能满足最基础的浏览需求,在涉及到数据汇总等更高维度的需求时,就不太方便了。所以我打算用 ElasticSearch + Kibana 来搭建一套可以满足日常浏览,查询和数据可视化需求的日志分析系统。
ElasticSearch 和 Kibana 是鼎鼎有名的 ELK 组合中两个重要成员。E 是 Elasticsearch,L 是Logstash,K 是 Kibana。它们一起组成了日志分析系统的经典解决方案。限于我目前的需求,以及不太充分的硬件资源,我准备舍弃这个组合中的 L,也就是 Logstash,只保留 E 和 K。它们一个负责数据存储,一个负责前端展示。
配置 Nginx 日志格式
因为绕过了 Logstash 处理并规范日志格式的流程,所以需要在日志的源头上就输出能在 ElasticSearch 上直接使用的日志格式。而直接塞给 ElasticSearch 首选的数据格式是 JSON,所以先来看看如何让 Nginx 直接输出 JSON 格式的日志内容。
Nginx 支持定义 JSON 格式的日志,不过需要自己来添加相关配置。在 nginx.conf 文件中的 log_format main ... 配置后插入这样一段配置:
log_format json escape=json '{"@timestamp":"$time_local",'
'"remote_addr":"$remote_addr",'
'"remote_user":"$remote_user",'
'"request":"$request",'
'"status":"$status",'
'"bytes":$body_bytes_sent,'
'"referer":"$http_referer",'
'"user_agent":"$http_user_agent",'
'"x_forwarded":"$http_x_forwarded_for",'
'"request_time":$request_time}';上面的配置定义了一种新的日志格式,格式名称为 json。escape=json 这行参数很关键,它让 Nginx 使用 JSON 转换日志内容,这样可以防范因为一些特殊字符而导致后面无法导入数据到 ElasticSearch 中的情况。后面的内容可以看出是在拼凑 JSON 字段和值,可以根据自己需要进行删减。
然后找到 access_log 访问日志配置项,把最后的 main 改为 json,表示要使用 JSON 格式的日志。完成配置后重启 Nginx,然后随便访问一下,应该会在日志文件中输出如下格式的访问记录:
{
"@timestamp":"27/Sep/2022:12:03:05 +0000",
"remote_addr":"10.0.2.100",
"remote_user":"",
"request":"GET /favicon.ico HTTP/1.1",
"status":"404",
"bytes":27,
"referer":"http://localhost/",
"user_agent":"Mozilla/5.0 (X11; Linux x86_64; rv:105.0) Gecko/20100101 Firefox/105.0",
"x_forwarded":"",
"request_time":0.006
}上面的内容在 Nginx 日志文件中是显示在一行的,这里为了方便查看做了格式化处理。
配置启动 ElasticSearch
有了日志数据,接下来需要准备存放数据的 ElasticSearch。推荐使用 Docker 方式的容器化安装方法,简单又轻松。我使用的是 Podman,跟 Docker 操作类似。
为了方便和 Kibana 服务互通,首先创建一个命名为 analysis 的容器网络:
podman network create analysis然后启动 ElasticSearch 容器服务:
podman run -it \
--userns keep-id \
--network analysis \
-e "discovery.type=single-node" \
-p 9200:9200 \
--name elasticsearch elasticsearch:8.4.0上面命令中的
--userns选项是 Podman 特有的,如果使用 Docker 不需要这个参数。
稍等片刻,等待拉取镜像并启动 ElasticSearch 服务。等出现下面类似的信息后,表示服务启动成功。
-> Elasticsearch security features have been automatically configured!
-> Authentication is enabled and cluster connections are encrypted.
-> Password for the elastic user (reset with `bin/elasticsearch-reset-password -u elastic`):
+85Kk8rSNEDAQdedHBB=
-> HTTP CA certificate SHA-256 fingerprint:
35e128d2041e8b92329ec5ab42c20922bdc3061587ea89581b782f447e94b78f
-> Configure Kibana to use this cluster:
* Run Kibana and click the configuration link in the terminal when Kibana starts.
* Copy the following enrollment token and paste it into Kibana in your browser (valid for the next 30 minutes):
eyJ2ZXIiOiI4LjQuMCIsImFkciI6WyIxMC44OS4wLjQ6OTIwMCJdLCJmZ3IiOiIzNWUxMjhkMjA0MWU4YjkyMzI5ZWM1YWI0MmMyMDkyMmJkYzMwNjE1ODdlYTg5NTgxYjc4MmY0NDdlOTRiNzhmIiwia2V5IjoiS2VUY2ZvTUJQZTBPcktPa0M0VG46UFl5WEJqWXNRc202Q25QRTZwd0pBUSJ9
-> Configure other nodes to join this cluster:
* Copy the following enrollment token and start new Elasticsearch nodes with `bin/elasticsearch --enrollment-token <token>` (valid for the next 30 minutes):
eyJ2ZXIiOiI4LjQuMCIsImFkciI6WyIxMC44OS4wLjQ6OTIwMCJdLCJmZ3IiOiIzNWUxMjhkMjA0MWU4YjkyMzI5ZWM1YWI0MmMyMDkyMmJkYzMwNjE1ODdlYTg5NTgxYjc4MmY0NDdlOTRiNzhmIiwia2V5IjoiSi1UY2ZvTUJQZTBPcktPa0M0VFI6d21IQlhZOU1SZmlVMmZ0TWREQTczdyJ9
If you're running in Docker, copy the enrollment token and run:
`docker run -e "ENROLLMENT_TOKEN=<token>" docker.elastic.co/elasticsearch/elasticsearch:8.4.0`上面输出的信息中,有两段比较重要:
Password for the elastic user ...这段下面的密码复制出来保存,等下登陆 Kibana 时要用。Configure Kibana to use this cluster ...这段下面的一长串随机字符复制出来保存,等下初始化 Kibana 服务时要用。
配置启动 Kibana
数据和数据存储服务都已经准备好,界面操作部分的 Kibana 是最后一步。同样使用容器方式来启动:
podman run --rm -it \
--userns keep-id \
--network analysis \
-p 5601:5601 \
--name kibana kibana:8.4.0等待容器启动成功,然后打开浏览器,输入 http://localhost:5601 访问 Kibana 配置界面。
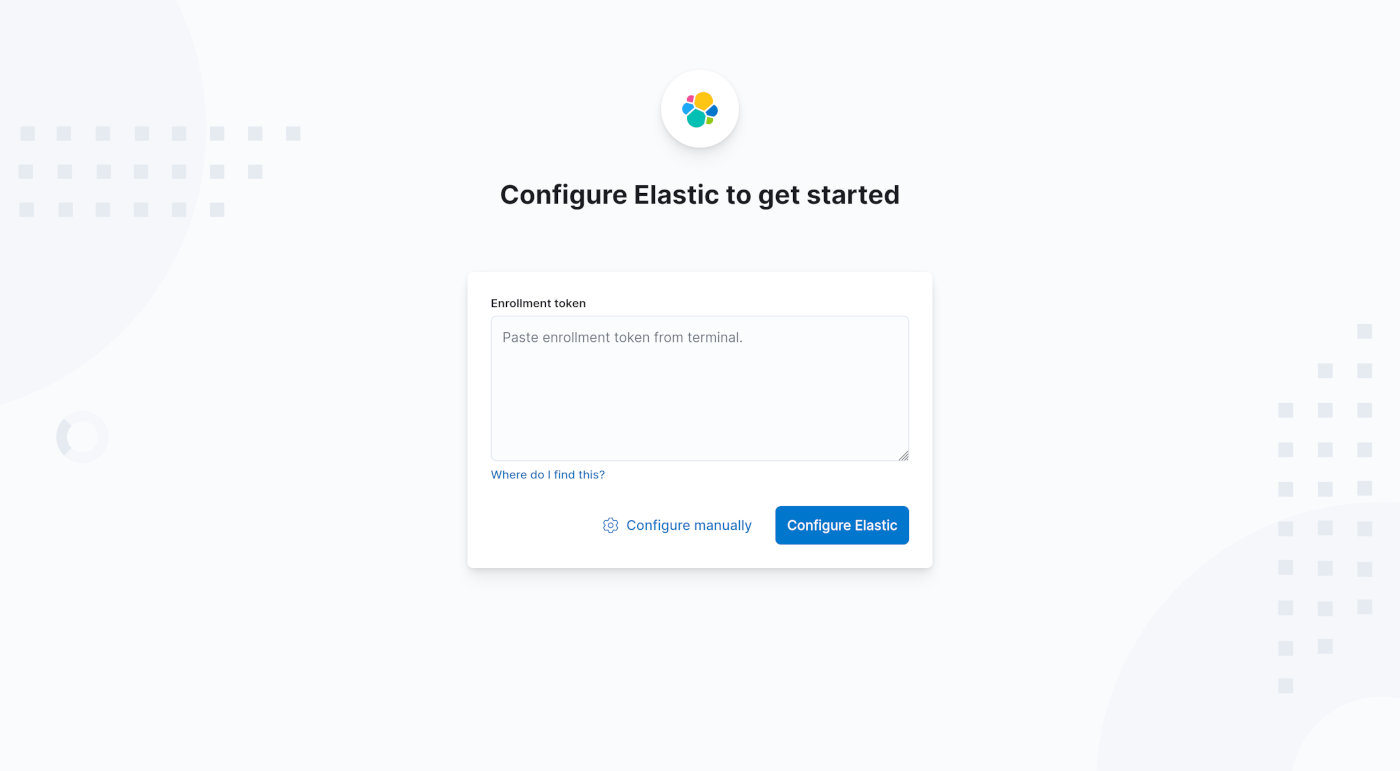
复制出上面 ElasticSearch 输出时保存的第二段长串随机字符,粘贴到这个文本框中,点击 「Configure Elastic」按钮,出现输入验证码界面。

查看 Kibana 容器的命令界面,会出现一行 Your verification code is: 的文本提示。复制后面的六位数验证码,然后回到浏览器端的界面粘贴进去,点击 「Verify」按钮继续。系统会开始自动配置流程,完成后会自动跳转到登陆界面。
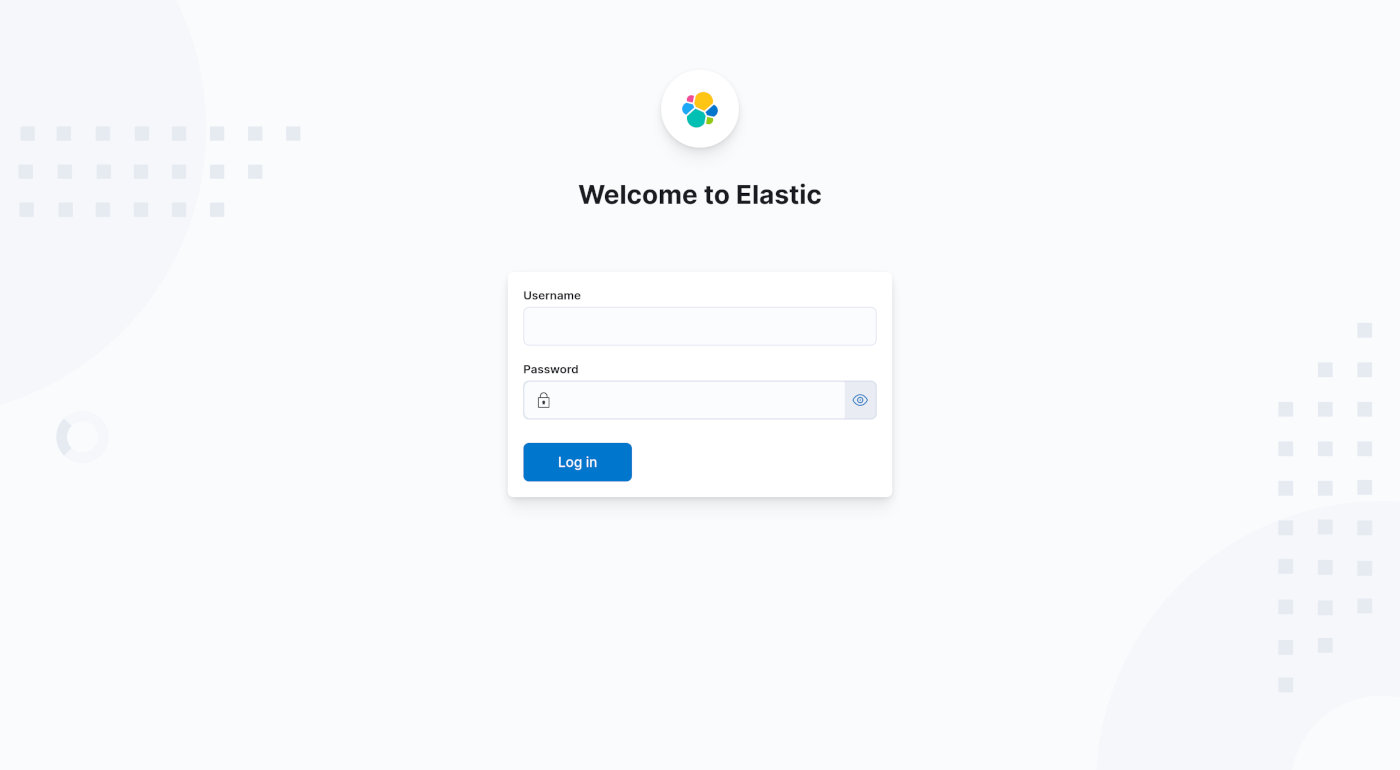
用户名输入 elastic,密码就是上面 ElasticSearch 输出信息中复制的第一段随机字符串。点击 「Log in」按钮,一切无误就能看到 Kinaba 的主页面了。
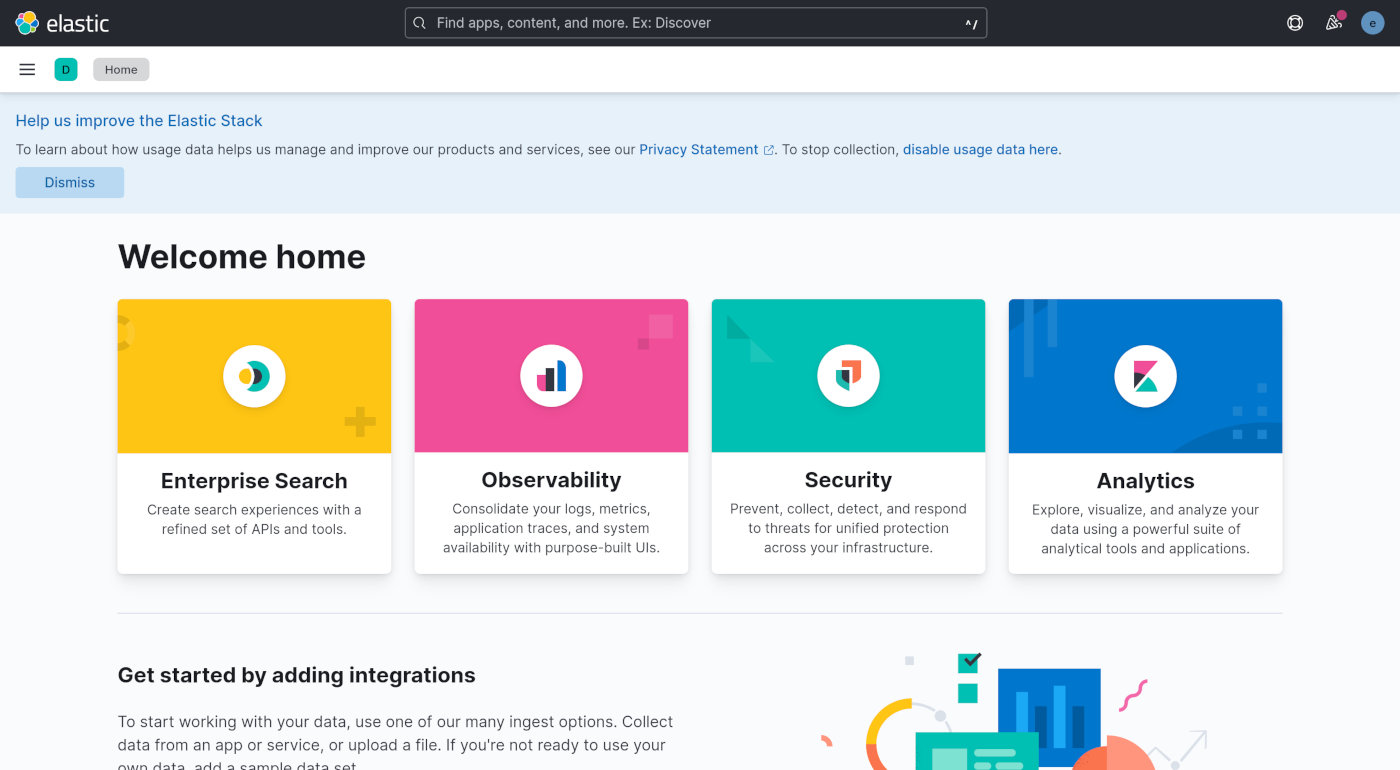
导入数据
准备好 JSON 格式的 Nginx 日志,如果是服务器上的,请提前下载到本机。然后在浏览器上点击 Kibana 首页左上角三条横线的菜单。
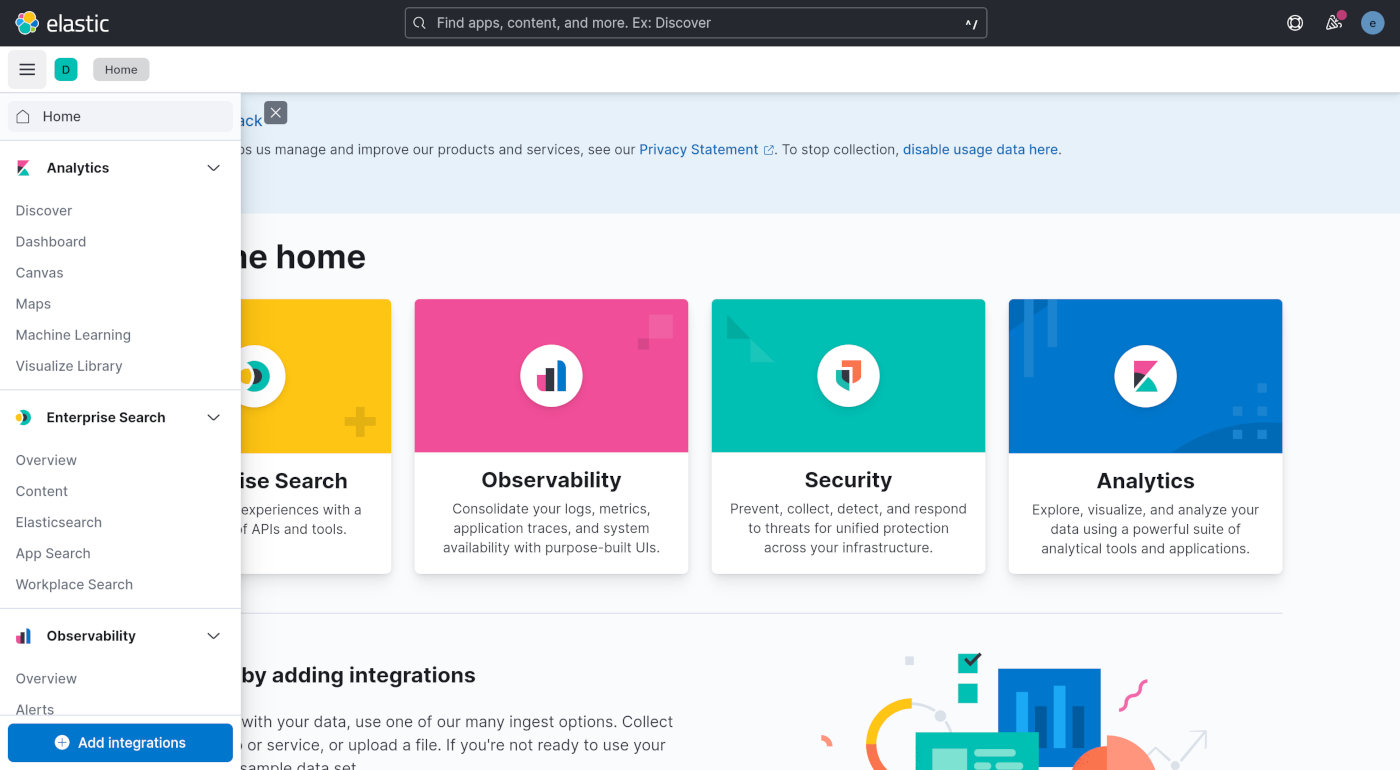
点最下方的「Add integrations」按钮。在打开页面的「Search for integrations」输入框中输入「upload」关键词,然后搜索。
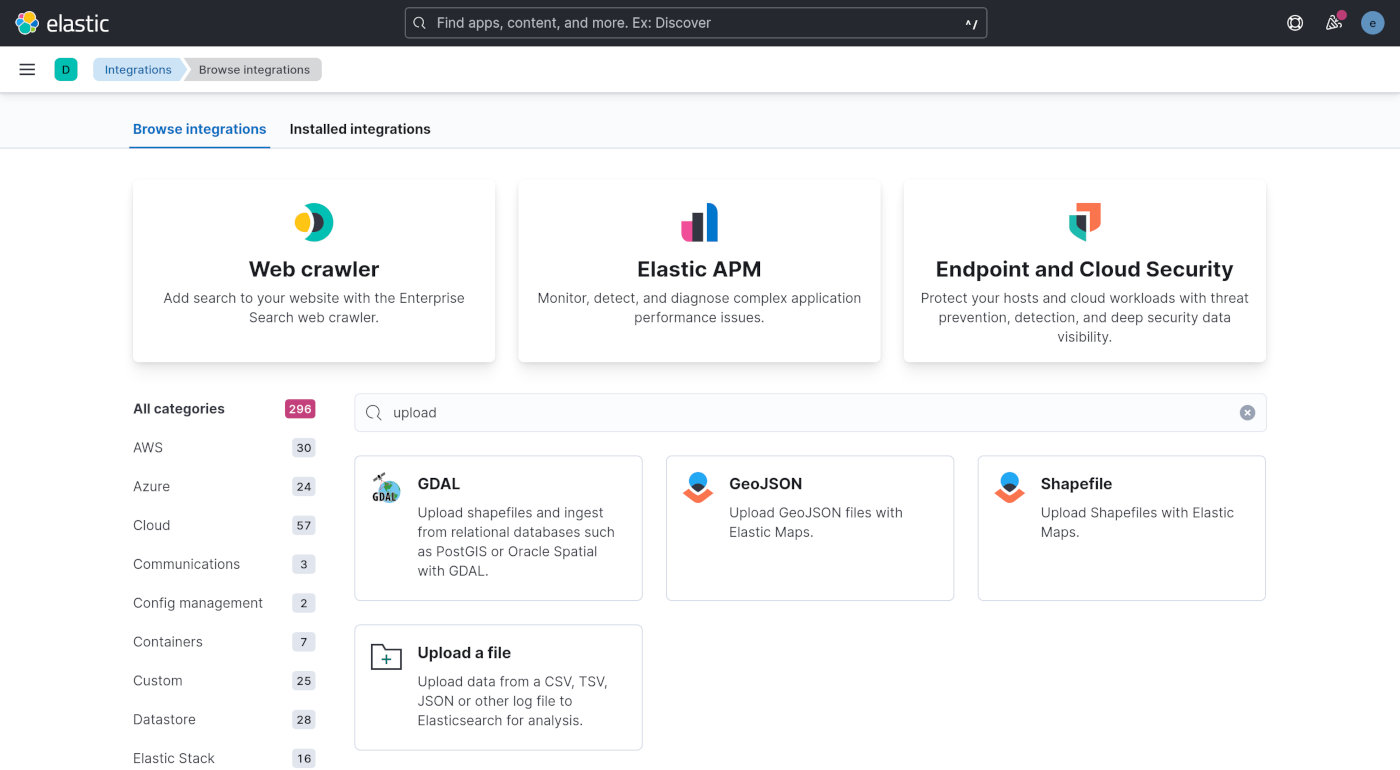
点击搜索结果中的 「Upload a file」内容块。再点一下最下方的「Select or drag and drop a file」链接区域,选择要分析的 Nginx 日志文件,并上传。Kibana 会显示数据预览界面。
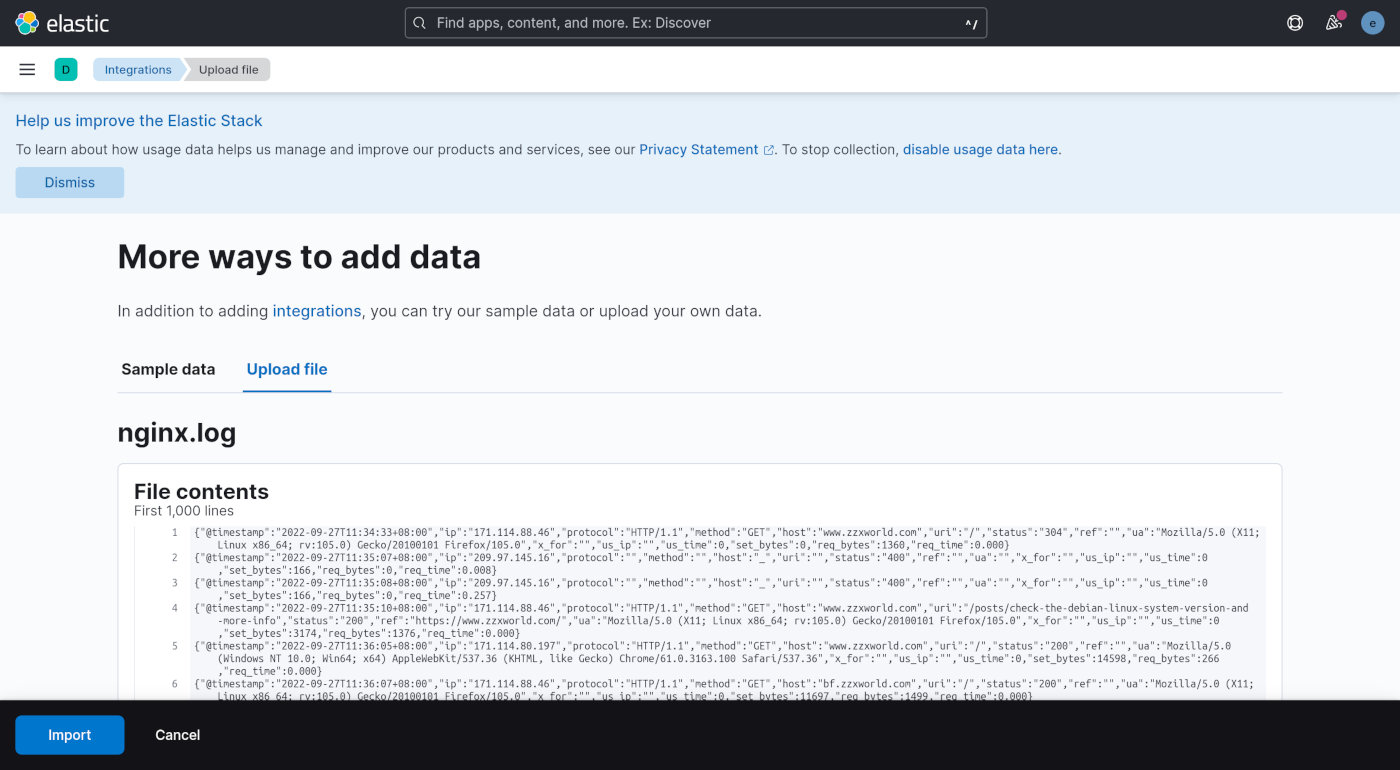
点击左下角的「Import」按钮确定导入数据,接下来会提示需要提供索引名称,随便输入一个,比如「nginx」,然后继续点「Import」按钮完成数据导入。
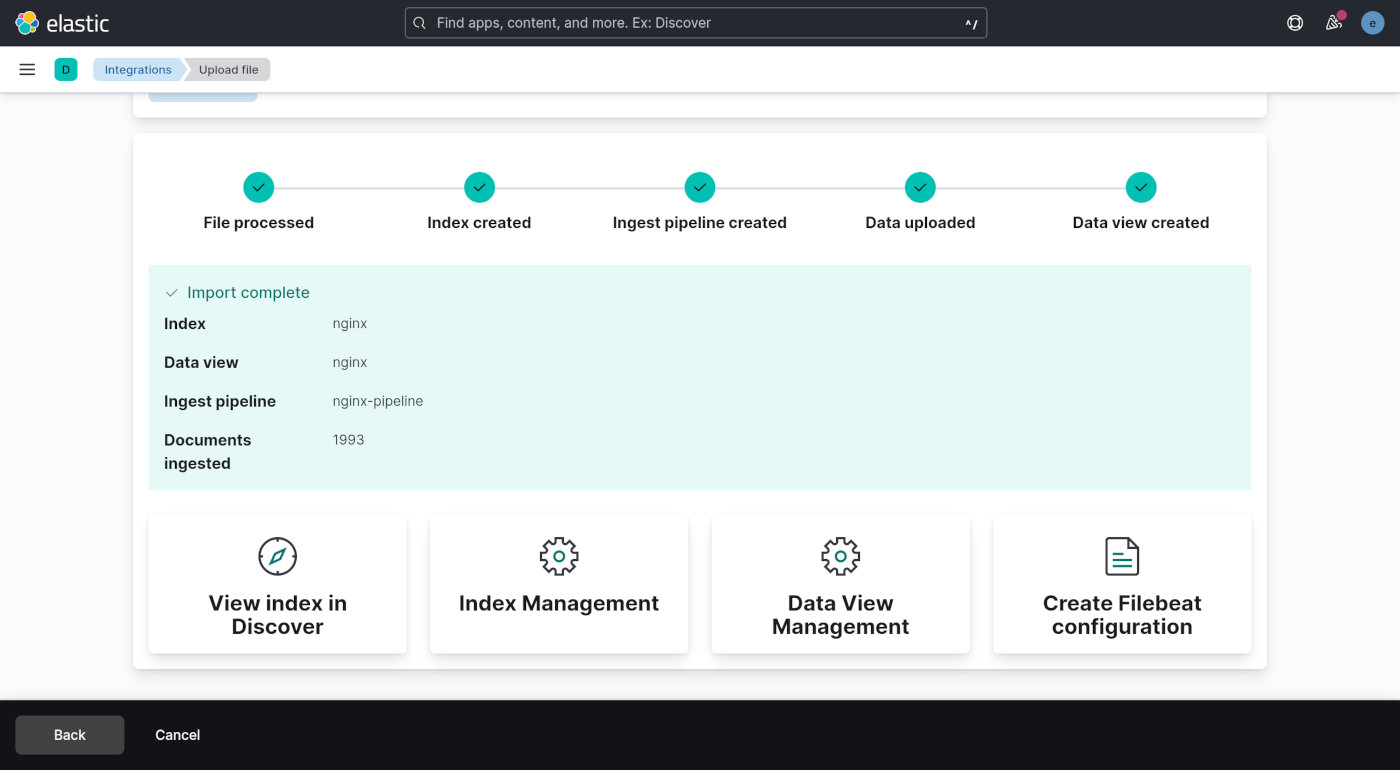
点击导入界面下方的「View index in Discover」就可以浏览导入数据了。
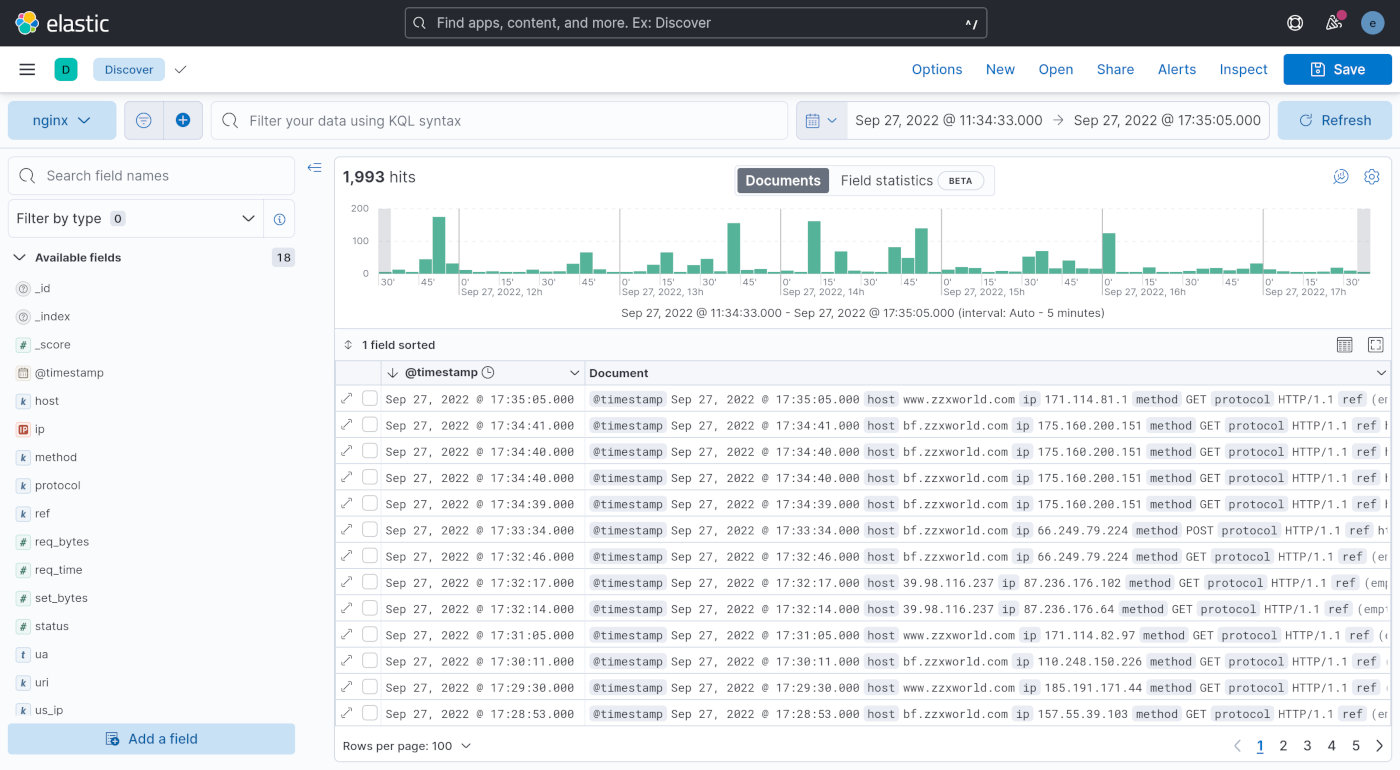
上图是我用线上数据展示的效果体验。看左侧的「Available fields」可以发现日志中定义的 JSON 字段都被识别出来了,接下来就只需根据自己的目的来选择使用。Kibana 提供了强大的数据查询和可视化功能,我需要的各种统计数据和图表完全可以通过它来实现。受限于篇幅,就不在本文展开了。
后续的流程优化想法
作为日常使用的系统,上面的步骤只能说是打通了流程。在日志导入这个环节,操作起来显然还不太方便。这一步我目前有两个思路。
- 写一个 Shell 脚本,每天需要看日志的时候通过执行这个 Shell 脚本下载日志数据,然后通过
curl命令调用 ElasticSearch 的 API 接口自动导入数据。 - 同样是通过执行 Shell 脚本,不过在导入环节使用 Filebeat,让它监控一个目录,我只需要把日志下载到这个目录,它就能自动把数据导入 ElasticSearch 中。